




If you are a Harry Potter fan, you may have heard of Jim Dale. The veteran actor-singer-composer is the narrator of all seven Harry Potter audio books, recorded between 1999 and 2007. The narration is longish — 117 hours and four minutes, in total. However, the time taken to record this was disproportionately more. Dale had to record some bits several times owing to mispronunciation, page flipping noise, using the wrong voice for a character or just skipping a line accidentally.
So, what other option do we have? Recording the entire book in a single take might not be humanly possible, but what humans cannot, machines can. Imagine if Dale could simply upload his voice samples, and a machine then clones his voice — complete with every pause, pronunciation and pitch — and automatically reproduces high-quality audio content. It would save everyone so much time.
Thankfully, this needs no magic, the solution has been created by Delhi-based start-up, Deepsync Technologies. Founded in December 2018 by Ishan Sharma and Rishikesh Kumar, the start-up uses deep learning and voice synthesis for ‘voice-cloning’, autonomously. Kumar, who doubles up as CTO, says that their high-quality .wav file is 10x cheaper than human production, as it eliminates the need for a studio and the process is 90% faster.
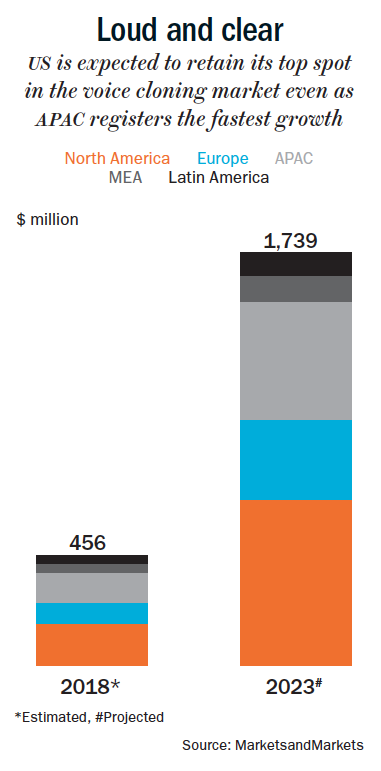
The duo seems to have set foot in a booming industry. A report by MarketsandMarkets states that the global voice-cloning market is expected to grow from $456 million in 2018 to $1,739 million by 2023 (See: Loud and clear). Sajan Paul, managing director and country manager for India and SAARC at Juniper Networks, says that AI and ML technologies, and our access to unlimited computing power have “dramatically” increased our ability to create multimedia content with “near realism”.

2 March 2026
Get the latest issue of Outlook Business

 With the boom in audio and video production, there is a demand for audio content in several languages, says Sachin Unni, investor and partner at Hong Kong-based accelerator Zeroth AI. Deepsync, which clones English as of now, is looking to add Indian language support in the coming months. It is among the eight Indian start-ups that are part of Zeroth AI’s first-ever accelerator programme in India. The other ventures backed by Zeroth also deal with AI-powered algorithms to — detect fake videos, advise millennials on investing, create drone delivery systems, and even tennis coaching via a smartwatch. Unni, who worked as a CTO for many years before turning an investor, says he is “always in search of amazing products built with a focus on future needs.”
With the boom in audio and video production, there is a demand for audio content in several languages, says Sachin Unni, investor and partner at Hong Kong-based accelerator Zeroth AI. Deepsync, which clones English as of now, is looking to add Indian language support in the coming months. It is among the eight Indian start-ups that are part of Zeroth AI’s first-ever accelerator programme in India. The other ventures backed by Zeroth also deal with AI-powered algorithms to — detect fake videos, advise millennials on investing, create drone delivery systems, and even tennis coaching via a smartwatch. Unni, who worked as a CTO for many years before turning an investor, says he is “always in search of amazing products built with a focus on future needs.”
In the Same Boat
Deepsync’s co-founders brought complementary skills to the table. After his B.Tech in electronics and instrumentation engineering from NIT, Silchar, in 2015, Kumar worked with software companies including HP, Nucleus Software and Humonics Global. He worked on a range of applications, from payments to chatbots, and on speech technology. On the other hand, Sharma, who completed his degree in computer science from SRM University, was keenly interested in the content industry. Two years ago, they met each other on GitHub, a programming website. “We discovered we were both interested in AI-generated media,” says Sharma.
A common problem they observed was that, to produce one hour of audio, six to seven hours of work (which includes narration, retakes, editing and post-production) needed to be done. Demand for content has increased exponentially, but the creation process remains highly manual. And since most text-to-speech softwares produce robotic speech (with minimal modulation), Kumar says, “We wanted to achieve high quality and high scale.” After identifying the problem, the two quit their jobs and started Deepsync in December 2018.
With Zeroth AI’s pre-seed funding, the duo spent hours coding and perfecting their algorithms. They tested their solution with companies such as travel technology provider Exploritage and edtech firm Udemy's creators and Sharma says their product cloned human voice with 97% accuracy. By October 2019, Deepsync was ready for commercial deployment.
Making Waves
How does Deepsync work? When a client approaches them to replicate a voice for content creation, the start-up asks for two things — the voice sample and permission of the owner approving voice cloning for that particular content. “It is a legal contract, which can be digitally signed by both parties,” explains Sharma. After this, the voice sample is fed into the system and uploaded onto a cloud server. The sample could be anywhere between 30-minutes to 20-hours long. “The lengthier the sample, the better is the quality of cloning,” says Sharma.
Using speech synthesis and algorithms modeled on the human brain, the system begins the process of ‘learning’ the voice, which means capturing various aspects of the sample including diction. The cloning process can take a few days to a week’s time, but it is a one-time process. Once cloned, the voice can be used to read out any text the client uploads, as often as needed.
Adrian Lee, senior director, Gartner, says that Deepsync’s solution is “an example of cutting edge technology combined with linguistics to create the most human-like audio output”. Lee believes it can find application in industries such as financial services, consumer goods, healthcare and entertainment. At present, Deepsync works with two multinational edtech firms, and those associated with self-help and spirituality business. In addition, it is looking to on-board voice artists and clients for audio-books and podcast creation.
The start-up’s revenue model is two-pronged. It charges for the content created and for the number of voices a client wants cloned. While the cost for the former varies from client to client, the charge for the latter is #100,000 to #150,000 per voice. The client gets access to the audio for a year, after which the contract has to be renewed.
The voice game
To be sure, Deepsync isn’t without company (See: Making itself heard). Globally, a number of firms have been investing in this technology. For instance, Google’s WaveLength provides a “framework for tackling many applications that rely on audio generation (for example, text-to-speech and music)”. Facebook’s VoiceLoop and Baidu’s Deep Voice also fall under this category. Gartner’s 2019 report lists companies such as Narrative Science, Arria NLG and AX Semantics as vendors engaged in the natural-language generation industry. At this stage, the co-founders of Deepsync consider all the other industry players as allies, since they are helping familiarise people with AI-generated content. Sharma says most companies use voice-cloning to produce long-format content, and unlike Deepsync, they are yet to invest in making them ‘human-like’. Experts concur that usage of such technology enables near-real precision, because AI can constantly keep learning. Unni adds that the start-up’s focus on audio-content market and bringing scale in Indian languages are among its biggest differentiators.
Flip Side
Now, there is another side to this cost-effective and time-saving innovation. And that is, the rising risk of deepfakes. A popular deepfake posted online is of Donald Trump lecturing Belgium on climate change and another is Facebook CEO Mark Zuckerberg declaring “whoever controls the data controls the future”. Even to a casual observer, these situations and speeches look highly improbable, so these deepfakes are easy to spot. However, most often, such manipulated content is mistaken for the real thing.
 “We predict deepfakes to be a rising threat in 2020 where cybercriminals will try to exploit huge amounts of data to generate fake audios and videos. This includes conversations that never happened and fake visuals to fool consumers,” says Ritesh Chopra, country director, NortonLifeLock. He adds that it is easy for cybercriminals to retrieve audio data, either through servers that store our voice commands to smart devices or just by engaging a target in a conversation. Lee echoes a similar view. “Opening this technology is risky. So, it is incumbent upon the producers to govern themselves,” he says.
“We predict deepfakes to be a rising threat in 2020 where cybercriminals will try to exploit huge amounts of data to generate fake audios and videos. This includes conversations that never happened and fake visuals to fool consumers,” says Ritesh Chopra, country director, NortonLifeLock. He adds that it is easy for cybercriminals to retrieve audio data, either through servers that store our voice commands to smart devices or just by engaging a target in a conversation. Lee echoes a similar view. “Opening this technology is risky. So, it is incumbent upon the producers to govern themselves,” he says.
While Unni acknowledges these concerns, he states the Deepsync team has always ensured security with a tight legal contract. Stringent check of the written permission, for instance, is a step in the right direction. Additionally, the co-founders are clear about sticking to a business-to-business model, as opening it to consumers would make it difficult to ensure compliance. But, gate-keeping isn’t the responsibility of content creators, such as Deepsync, alone. Paul states, “Social media platforms should also be working on advanced algorithms to filter deepfake content from their domain. While ethical use should be nurtured, there should also be an industry-wide collaboration to establish real versus fake.”
For the coming year, Deepsync has set its ambition high. For one, the founders say that currently, the system reproduces audio in a narrative tone with accurate inflection, but it lacks human emotions such as happiness, anger or sadness. The duo is working on introducing these in the coming months. They are also working on a library of voices. That is, a voice artist can sign up with Deepsync to offer his/her voice and a client can then pick from a repository of such samples. Clearly, the two are optimistic about their prospects. How far and how soon they reach their goals remains to be seen. Or perhaps heard!




